




Passive DNS collection and monitoring built with Golang, Clickhouse and Grafana: dnsmonster implements a packet sniffer for DNS traffic. It can accept traffic from a pcap file, a live interface or a dnstap socket, and can be used to index and store thousands of DNS queries per second (it has shown to be capable of indexing 200k+ DNS queries per second on a commodity computer).
It aims to be scalable, simple and easy to use, and help security teams to understand the details about an enterprise’s DNS traffic. dnsmonster does not look to follow DNS conversations, rather it aims to index DNS packets as soon as they come in. It also does not aim to breach the privacy of the end-users, with the ability to mask source IP from 1 to 32 bits, making the data potentially untraceable.
IMPORTANT NOTE: The code before version 1.x is considered beta quality and is subject to breaking changes. Please check the release notes for each tag to see the list of breaking scenarios between each release, and how to mitigate potential data loss.
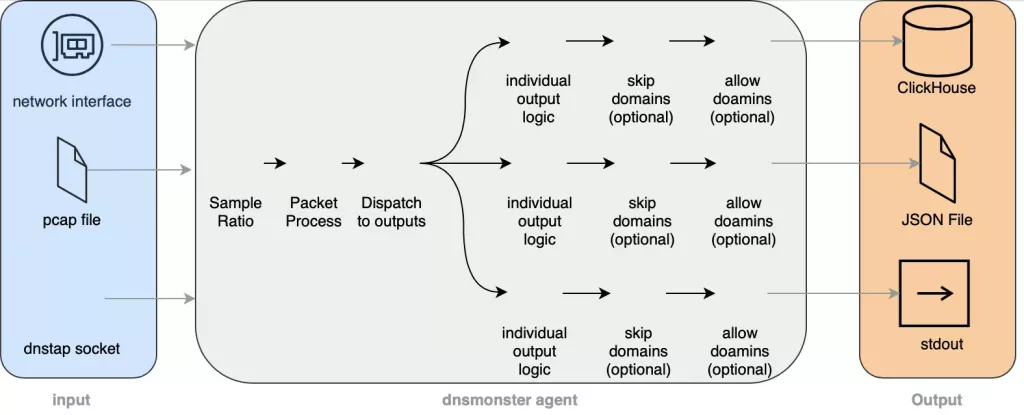
Main features
- Can use Linux’s afpacket and zero-copy packet capture.
- Supports BPF
- Can fuzz source IP to enhance privacy
- Can have a pre-processing sampling ratio
- Can have a list of “skip” fqdns to avoid writing some domains/suffix/prefix to storage, thus improving DB performance
- Can have a list of “allow” domains to only log hits of certain domains in Clickhouse/Stdout/File
- Modular output with different logic per output stream. Currently stdout/file/clickhouse
- Hot-reload of skip and allow domain files
- Automatic data retention policy using ClickHouse’s TTL attribute
- Built-in dashboard using Grafana
- Can be shipped as a single, statically-linked binary
- Ability to be configured using Env variables, command line options or configuration file
- Ability to sample output metrics using ClickHouse’s SAMPLE capability
- High compression ratio thanks to ClickHouse’s built-in LZ4 storage
- Supports DNS Over TCP, Fragmented DNS (udp/tcp) and IPv6
- Supports dnstrap over Unix socket or TCP
Manual Installation
Linux
For afpacket v3 support, you need to use kernel 3.x+. Any Linux distro since 5 years ago is shipped with a 3.x+ version so it should work out of the box. The release binary is shipped as a statically-linked binary and shouldn’t need any dependencies and will work out of the box. If your distro is not running the pre-compiled version properly, please submit an issue with the details and build dnsmonster manually using this section Build Manually.
Windows
Windows release of the binary depends on npcap to be installed. After installation, the binary should work out of the box. I’ve tested it in a Windows 10 environment and it ran without an issue. To find interface names to give -devName parameter and start sniffing, you’ll need to do the following:
- open cmd.exe (probably as Admin) and run the following: getmac.exe, you’ll see a table with your interfaces’ MAC address and a Transport Name column with something like this: \Device\Tcpip_{16000000-0000-0000-0000-145C4638064C}
- run dnsmonster.exe in cmd.exe like this:
dnsmonster.exe \Device\NPF_{16000000-0000-0000-0000-145C4638064C}
Note that you should change \Tcpip from getmac.exe to \NPF inside dnsmonster.exe.
Since afpacket is a Linux feature and Windows is not supported, useAfpacket and its related options will not work and will cause unexpected behavior on Windows.
Architecture
AIO Installation using Docker
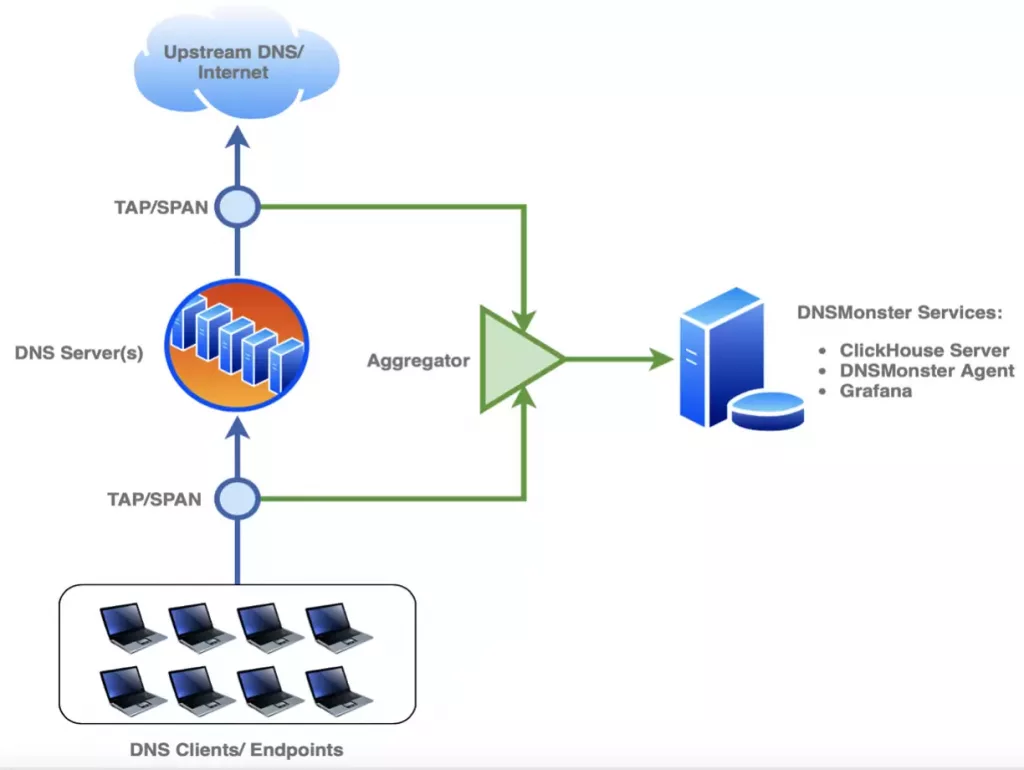
In the example diagram, the egress/ingress of the DNS server traffic is captured, after that, an optional layer of packet aggregation is added before hitting the DNSMonster Server. The outbound data going out of DNS Servers is quite useful to perform cache and performance analysis on the DNS fleet. If an aggregator is not available for you, you can have both TAPs connected directly to DNSMonster and have two DNSMonster Agents looking at the traffic.
running ./autobuild.sh creates multiple containers:
- Multiple instances of dnsmonster to look at the traffic on any interface. Interface list will be prompted as part of autobuild.sh
- An instance of clickhouse to collect dnsmonster’s output and saves all the logs/data to a data and logs directory. Both will be prompted as part of autobuild.sh
- An instance of grafana looking at the clickhouse data with pre-built dashboard.
AIO Demo

Also See – What is DNS Rebinding Attack?
Enterprise Deployment
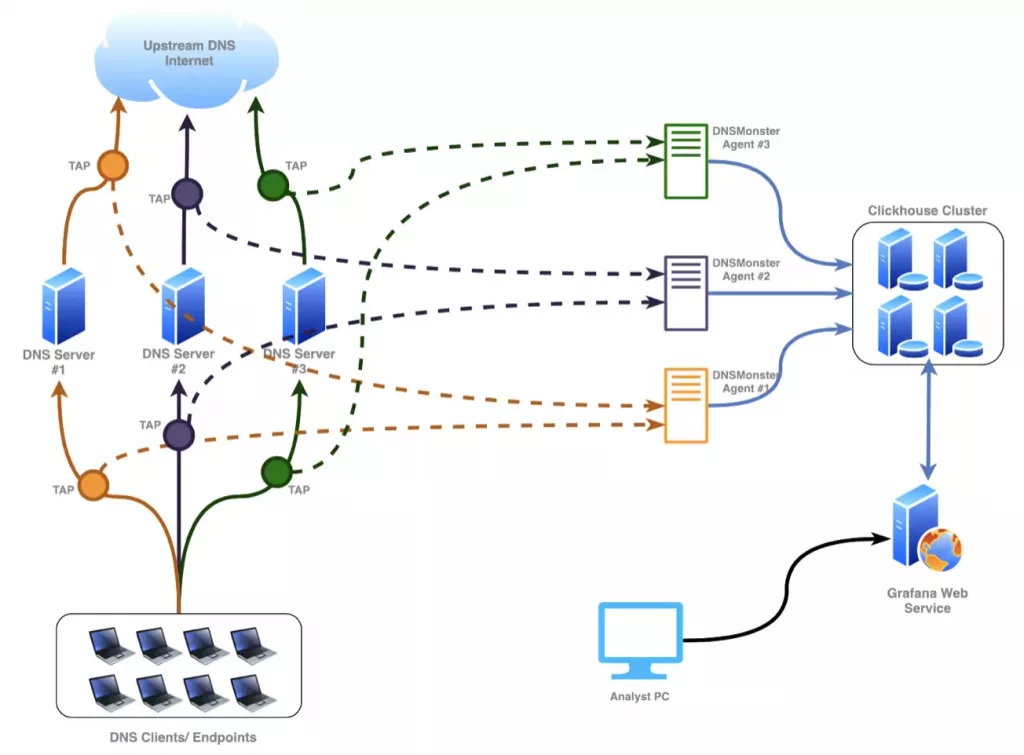
Set up a ClickHouse Cluster
Clickhouse website provides an excellent tutorial on how to create a cluster with a “virtual” table, reference. Note that DNS_LOG has to be created virtually in this cluster in order to provide HA and load balancing across the nodes.
Configuration of Agent as well as Grafana is Coming soon!
Configuration
DNSMonster can be configured using 3 different methods. Command line options, Environment variables and configuration file. Order of precedence:
- Command line options
- Environment variables
- Configuration file
- Default values
Command line options
dnsmonster
general:
--config= path to config file
[$DNSMONSTER_CONFIG]
--gcTime= Garbage Collection interval for tcp
assembly and ip defragmentation
(default: 10s) [$DNSMONSTER_GCTIME]
--captureStatsDelay= Duration to calculate interface stats
(default: 1s)
[$DNSMONSTER_CAPTURESTATSDELAY]
--printStatsDelay= Duration to print capture and database
stats (default: 10s)
[$DNSMONSTER_PRINTSTATSDELAY]
--maskSize= Mask source IPs by bits. 32 means all
the bits of IP is saved in DB
(default: 32) [$DNSMONSTER_MASKSIZE]
--serverName= Name of the server used to index the
metrics. (default: default)
[$DNSMONSTER_SERVERNAME]
--tcpAssemblyChannelSize= Size of the tcp assembler (default:
1000)
[$DNSMONSTER_TCPASSEMBLYCHANNELSIZE]
--tcpResultChannelSize= Size of the tcp result channel
(default: 1000)
[$DNSMONSTER_TCPRESULTCHANNELSIZE]
--tcpHandlerCount= Number of routines used to handle tcp
assembly (default: 1)
[$DNSMONSTER_TCPHANDLERCOUNT]
--resultChannelSize= Size of the result processor channel
size (default: 100000)
[$DNSMONSTER_RESULTCHANNELSIZE]
--logLevel=[0|1|2|3|4] Set debug Log level, 0:PANIC, 1:ERROR,
2:WARN, 3:INFO, 4:DEBUG (default: 3)
[$DNSMONSTER_LOGLEVEL]
--defraggerChannelSize= Size of the channel to send packets to
be defragged (default: 500)
[$DNSMONSTER_DEFRAGGERCHANNELSIZE]
--defraggerChannelReturnSize= Size of the channel where the
defragged packets are returned
(default: 500)
[$DNSMONSTER_DEFRAGGERCHANNELRETURNSIZ-
E]
--cpuprofile= write cpu profile to file
[$DNSMONSTER_CPUPROFILE]
--memprofile= write memory profile to file
[$DNSMONSTER_MEMPROFILE]
--gomaxprocs= GOMAXPROCS variable (default: -1)
[$DNSMONSTER_GOMAXPROCS]
--packetLimit= Limit of packets logged to clickhouse
every iteration. Default 0 (disabled)
(default: 0) [$DNSMONSTER_PACKETLIMIT]
--skipDomainsFile= Skip outputing domains matching items
in the CSV file path. Can accept a URL
(http:// or https://) or path
[$DNSMONSTER_SKIPDOMAINSFILE]
--skipDomainsRefreshInterval= Hot-Reload skipDomainsFile interval
(default: 60s)
[$DNSMONSTER_SKIPDOMAINSREFRESHINTERVA-
L]
--skipDomainsFileType= skipDomainsFile type. Options: csv and
hashtable. Hashtable is ONLY fqdn, csv
can support fqdn, prefix and suffix
logic but it's much slower (default:
csv) [$DNSMONSTER_SKIPDOMAINSFILETYPE]
--allowDomainsFile= Allow Domains logic input file. Can
accept a URL (http:// or https://) or
path [$DNSMONSTER_ALLOWDOMAINSFILE]
--allowDomainsRefreshInterval= Hot-Reload allowDomainsFile file
interval (default: 60s)
[$DNSMONSTER_ALLOWDOMAINSREFRESHINTERV-
AL]
--allowDomainsFileType= allowDomainsFile type. Options: csv
and hashtable. Hashtable is ONLY fqdn,
csv can support fqdn, prefix and
suffix logic but it's much slower
(default: csv)
[$DNSMONSTER_ALLOWDOMAINSFILETYPE]
--skipTLSVerification Skip TLS verification when making
HTTPS connections
[$DNSMONSTER_SKIPTLSVERIFICATION]
--saveFullQuery Save full packet query and response in
JSON format.
[$DNSMONSTER_SAVEFULLQUERY]
--version show version and quit.
[$DNSMONSTER_VERSION]help:
-h, --help Print this help to stdout
--manPage Print Manpage for dnsmonster to stdout
--bashCompletion Print bash completion script to stdout
--fishCompletion Print fish completion script to stdout
--writeConfig= generate a config file based on
current inputs (flags, input config
file and environment variables) and
write to provided path
capture:
--devName= Device used to capture
[$DNSMONSTER_DEVNAME]
--pcapFile= Pcap filename to run
[$DNSMONSTER_PCAPFILE]
--dnstapSocket= dnstrap socket path. Example:
unix:///tmp/dnstap.sock,
tcp://127.0.0.1:8080
[$DNSMONSTER_DNSTAPSOCKET]
--port= Port selected to filter packets
(default: 53) [$DNSMONSTER_PORT]
--sampleRatio= Capture Sampling by a:b. eg
sampleRatio of 1:100 will process 1
percent of the incoming packets
(default: 1:1)
[$DNSMONSTER_SAMPLERATIO]
--dnstapPermission= Set the dnstap socket permission, only
applicable when unix:// is used
(default: 755)
[$DNSMONSTER_DNSTAPPERMISSION]
--packetHandlerCount= Number of routines used to handle
received packets (default: 1)
[$DNSMONSTER_PACKETHANDLERCOUNT]
--packetChannelSize= Size of the packet handler channel
(default: 100000)
[$DNSMONSTER_PACKETCHANNELSIZE]
--afpacketBuffersizeMb= Afpacket Buffersize in MB (default:
64) [$DNSMONSTER_AFPACKETBUFFERSIZEMB]
--filter= BPF filter applied to the packet
stream. If port is selected, the
packets will not be defragged.
(default: ((ip and (ip[9] == 6 or
ip[9] == 17)) or (ip6 and (ip6[6] ==
17 or ip6[6] == 6 or ip6[6] == 44))))
[$DNSMONSTER_FILTER]
--useAfpacket Use AFPacket for live captures.
Supported on Linux 3.0+ only
[$DNSMONSTER_USEAFPACKET]
output:
--clickhouseAddress= Address of the clickhouse database to
save the results (default:
localhost:9000)
[$DNSMONSTER_CLICKHOUSEADDRESS]
--clickhouseDelay= Interval between sending results to
ClickHouse (default: 1s)
[$DNSMONSTER_CLICKHOUSEDELAY]
--clickhouseDebug Debug Clickhouse connection
[$DNSMONSTER_CLICKHOUSEDEBUG]
--clickhouseOutputType=[0|1|2|3|4] What should be written to clickhouse.
options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_CLICKHOUSEOUTPUTTYPE]
--clickhouseBatchSize= Minimun capacity of the cache array
used to send data to clickhouse. Set
close to the queries per second
received to prevent allocations
(default: 100000)
[$DNSMONSTER_CLICKHOUSEBATCHSIZE]
--fileOutputType=[0|1|2|3|4] What should be written to file.
options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_FILEOUTPUTTYPE]
--fileOutputPath= Path to output file. Used if
fileOutputType is not none
[$DNSMONSTER_FILEOUTPUTPATH]
--stdoutOutputType=[0|1|2|3|4] What should be written to stdout.
options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_STDOUTOUTPUTTYPE]
--syslogOutputType=[0|1|2|3|4] What should be written to Syslog
server. options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_SYSLOGOUTPUTTYPE]
--syslogOutputEndpoint= Syslog endpoint address, example:
udp://127.0.0.1:514,
tcp://127.0.0.1:514. Used if
syslogOutputType is not none
[$DNSMONSTER_SYSLOGOUTPUTENDPOINT]
--kafkaOutputType=[0|1|2|3|4] What should be written to kafka.
options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_KAFKAOUTPUTTYPE]
--kafkaOutputBroker= kafka broker address, example:
127.0.0.1:9092. Used if
kafkaOutputType is not none
[$DNSMONSTER_KAFKAOUTPUTBROKER]
--kafkaOutputTopic= Kafka topic for logging (default:
dnsmonster)
[$DNSMONSTER_KAFKAOUTPUTTOPIC]
--kafkaBatchSize= Minimun capacity of the cache array
used to send data to Kafka (default:
1000) [$DNSMONSTER_KAFKABATCHSIZE]
--kafkaBatchDelay= Interval between sending results to
Kafka if Batch size is not filled
(default: 1s)
[$DNSMONSTER_KAFKABATCHDELAY]
--elasticOutputType=[0|1|2|3|4] What should be written to elastic.
options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_ELASTICOUTPUTTYPE]
--elasticOutputEndpoint= elastic endpoint address, example:
http://127.0.0.1:9200. Used if
elasticOutputType is not none
[$DNSMONSTER_ELASTICOUTPUTENDPOINT]
--elasticOutputIndex= elastic index (default: default)
[$DNSMONSTER_ELASTICOUTPUTINDEX]
--elasticBatchSize= Send data to Elastic in batch sizes
(default: 1000)
[$DNSMONSTER_ELASTICBATCHSIZE]
--elasticBatchDelay= Interval between sending results to
Elastic if Batch size is not filled
(default: 1s)
[$DNSMONSTER_ELASTICBATCHDELAY]
--splunkOutputType=[0|1|2|3|4] What should be written to HEC. options:
; 0: Disable Output
; 1: Enable Output without any filters
; 2: Enable Output and apply
skipdomains logic
; 3: Enable Output and apply
allowdomains logic
; 4: Enable Output and apply both skip
and allow domains logic (default: 0)
[$DNSMONSTER_SPLUNKOUTPUTTYPE]
--splunkOutputEndpoints= splunk endpoint address, example:
http://127.0.0.1:8088. Used if
splunkOutputType is not none
[$DNSMONSTER_SPLUNKOUTPUTENDPOINTS]
--splunkOutputToken= Splunk HEC Token (default:
00000000-0000-0000-0000-000000000000)
[$DNSMONSTER_SPLUNKOUTPUTTOKEN]
--splunkOutputIndex= Splunk Output Index (default: temp)
[$DNSMONSTER_SPLUNKOUTPUTINDEX]
--splunkOutputSource= Splunk Output Source (default:
dnsmonster)
[$DNSMONSTER_SPLUNKOUTPUTSOURCE]
--splunkOutputSourceType= Splunk Output Sourcetype (default:
json)
[$DNSMONSTER_SPLUNKOUTPUTSOURCETYPE]
--splunkBatchSize= Send data to HEC in batch sizes
(default: 1000)
[$DNSMONSTER_SPLUNKBATCHSIZE]
--splunkBatchDelay= Interval between sending results to
HEC if Batch size is not filled
(default: 1s)
[$DNSMONSTER_SPLUNKBATCHDELAY]
Environment variables
all the flags can also be set via env variables. Keep in mind that the name of each parameter is always all upper case and the prefix for all the variables is “DNSMONSTER”. Example:
$ export DNSMONSTER_PORT=53
$ export DNSMONSTER_DEVNAME=lo
$ sudo -E dnsmonster
Configuration file
you can run dnsmonster using the following command to in order to use configuration file:
$ sudo dnsmonster -config=dnsmonster.cfg
Or you can use environment variables to set the configuration file path
$ export DNSMONSTER_CONFIG=dnsmonster.cfg
$ sudo -E dnsmonster
What’s the retention policy
The default retention policy for the DNS data is set to 30 days. You can change the number by building the containers using ./autobuild.sh. Since ClickHouse doesn’t have an internal timestamp, the TTL will look at incoming packet’s date in pcap files. So while importing old pcap files, ClickHouse may automatically start removing the data as they’re being written and you won’t see any actual data in your Grafana. To fix that, you can change TTL to a day older than your earliest packet inside the PCAP file.
NOTE: to change a TTL at any point in time, you need to directly connect to the Clickhouse server using a clickhouse client and run the following SQL statement (this example changes it from 30 to 90 days):
ALTER TABLE DNS_LOG MODIFY TTL DnsDate + INTERVAL 90 DAY;`
NOTE: The above command only changes TTL for the raw DNS log data, which is the majority of your capacity consumption. To make sure that you adjust the TTL for every single aggregation table, you can run the following:
ALTER TABLE DNS_LOG MODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_DOMAIN_COUNTMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_DOMAIN_UNIQUEMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_PROTOCOLMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_GENERAL_AGGREGATIONSMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_EDNSMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_OPCODEMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_TYPEMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_CLASSMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_RESPONSECODEMODIFY TTL DnsDate + INTERVAL 90 DAY;
ALTER TABLE.inner.DNS_IP_MASKMODIFY TTL DnsDate + INTERVAL 90 DAY;
Sampling and Skipping
pre-process sampling
dnsmonster supports pre-processing sampling of packet using a simple parameter: sampleRatio. this parameter accepts a “ratio” value, like “1:2”. “1:2” means for each 2 packet that arrives, only process one of them (50% sampling). Note that this sampling happens AFTER bpf filters and not before. if you have an issue keeping up with the volume of your DNS traffic, you can set this to something like “2:10”, meaning 20% of the packets that pass your bpf filter, will be processed by dnsmonster.
skip domains
dnsmonster supports a post-processing domain skip list to avoid writing noisy, repetitive data to your Database. The domain skip list is a csv-formatted file, with only two columns: a string and a logic for that particular string. dnsmonster supports three logics: prefix, suffix and fqdn. prefix and suffix means that only the domains starting/ending with the mentioned string will be skipped to be written to DB. Note that since we’re talking about DNS questions, your string will most likely have a trailing . that needs to be included in your skip list row as well (take a look at skipdomains.csv.sample for a better view). You can also have a full FQDN match to avoid writing highly noisy FQDNs into your database.
allow domains
dnsmonster has the concept of “allowdomains”, which helps building the detection if certain FQDNs, prefixes or suffixes are present in the DNS traffic. Given the fact that dnsmonster supports multiple output streams with different logic for each one, it’s possible to collect all DNS traffic in ClickHouse, but collect only “allowlist” domains in stdout or in a file in the same instance of dnsmonster.
SAMPLE in clickhouse SELECT queries
By default, the main tables created by tables.sql (DNS_LOG) file have the ability to sample down a result as needed, since each DNS question has a semi-unique UUID associated with it. For more information about SAMPLE queries in Clickhouse, please check out this document.
Supported Outputs
- Clickhouse
- Kafka
- Elasticsearch
- Splunk HEC
- Stdout
- File
- Syslog
Build Manually
Make sure you have libpcap-devel and linux-headers packages installed.
go get gitlab.com/mosajjal/dnsmonster/src
Static Build
$ git clone https://gitlab.com/mosajjal/dnsmonster
$ cd dnsmonster/src/
$ go get
$ go build --ldflags "-L /root/libpcap-1.9.1/libpcap.a -linkmode external -extldflags \"-I/usr/include/libnl3 -lnl-genl-3 -lnl-3 -static\"" -a -o dnsmonster
For more information on how the statically linked binary is created, take a look at this Dockerfile.
There are two binary flavours released for each release. A statically-linked self-contained binary built against musl on Alpine Linux, which will be maintained here, and dynamically linked binaries for Windows and Linux, which will depend on libpcap. These releases are built against glibc so they will have a slight performance advantage over musl. These builds will be available in the release section of Github repository.
Roadmap
- Down-sampling capability for SELECT queries
- Adding afpacket support
- Configuration file option
- Exclude FQDNs from being indexed
- FQDN whitelisting to only log certain domains
- dnstap support
- Kafka output support
- Ability to load allowDomains and skipDomains from HTTP(S) endpoints
- Elasticsearch output support
- Splunk HEC output support
- Syslog output support
- Grafana dashboard performance improvements
- Splunk Dashboard
- Kibana Dashbaord
- Optional SSL for Clickhouse
- De-duplication support
- Getting the data ready to be used for ML & Anomaly Detection
- remove libpcap dependency and move to pcapgo
- Clickhouse versioning and migration tool
- statsd and Prometheus support





